
Introduction
Here at Boston, we have access to some of the latest and most powerful hardware on the market. Today we will be taking a look at NVIDIAs RTX Pro 6000 Blackwell Workstation edition. With 96GB of GDDR7 memory, 5th Generation Tensor Cores and 4th Generation Ray Tracing Cores, an AI Management Processor amongst other features, this mammoth GPU has incredible power with 600W at its disposal.


Specs
Below is a summary of all the features the NVIDIA RTX Pro 6000 has to offer:
| Category | Specification |
| GPU Architecture | NVIDIA Blackwell |
| CUDA Cores | 24,064 |
| Tensor Cores | 5th Generation |
| Ray Tracing Cores | 4th Generation |
| AI Performance | 4000 AI TOPS |
| FP32 (Single Precision) | 125 TFLOPS |
| RT Core Performance | 380 TFLOPS |
| GPU Memory | 96GB GDDR7 with ECC |
| Memory Interface | 512-bit |
| Memory Bandwidth | 1792 GB/s |
| System Interface | PCIe 5.0 x16 |
| Display Connectors | 4x DisplayPort 2.1b |
| Max Displays Supported | >4x 4096×2160 @120 Hz>4x 5120×2880 @60 Hz>2x 7680×4320 @60 Hz |
| Video Engines | 4x NVENC (9th Gen), 4x NVDEC (6th Gen) |
| MIG Support | Up to 4×24 GB, 2×48 GB, or 1×96 GB |
| Power Consumption | 600W (Total board power) |
| Power Connector | 1x PCIe CEM5 16-pin |
| Thermal Solution | Double-flow-through |
| Form Factor | 5.4″ H × 12″ L, dual-slot, extended height |
| Graphics APIs | DirectX 12, Shader Model 6.6, OpenGL 4.6, Vulkan 1.3 |
| Compute APIs | CUDA 12.8, OpenCL 3.0, DirectCompute |
View Product Datasheet
Benchmarking
Of course, we were more than excited about putting the GPU through its paces. We completed numerous tests with interesting results against the previous generations actively cooled NVIDIA RTX 6000 Ada (at 300W) and the current consumer grade NVIDIA GeForce RTX 5090.
Note: The consumer grade GPU is not built for 24/7 continuous use and as such are not suited for enterprise workloads, greatly reducing the life expectancy of the card.
| Specification | NVIDIA 5090 | NVIDIA RTX 6000 Ada |
| CUDA Cores | 21,760 | 18,176 |
| Shader Cores Architecture | Blackwell | Ada Lovelace |
| Tensor Cores Generation | 5th Generation | 4th Generation |
| Single Precision Performance | 318 TFLOPS | 91.1 TFLOPS |
| Memory Type & Size | 32GB GDDR7 | 48GB GDDR6 |
| Memory Interface Width | 512-bit | 384-bit |
| Memory Bandwidth | 1.79 TB/s | 960 GB/s |
| PCI Express Version | Gen 5 | Gen 4 |
| Power Consumption | 575W | 300W |
| Display Connectors | 3x DisplayPort (2.1b), 1x HDMI (2.1b) | 4x DisplayPort (1.4a) |
| Max Digital Resolution | 4 x 3840 x 2160 @ 480Hz or 7680x4320 @ 165Hz with DSC | 4x 4096x2160 @120 Hz, 4 x 5120 x 2880 at 60 Hz or 2x 7680 x 4320 @ 60Hz |
| Max Monitors Supported | Up to 4 | Up to 4 |
| NVLink (SLI) | No | No |
| Encoder/Decoder | 3x NVENC 9th Gen, 2x NVDEC 6th Gen, AV1 Encode/Decode | 3x NVENC 8th Gen, 3x NVDEC 7th Gen, AV1 Encode/Decode |
| VR Ready | Yes | Yes |
| Ray Tracing Cores Generation | 4th Generation (178 RT Cores) | 3rd Generation (142 RT Cores) |
NVIDIA RTX 6000 Ada Specs
NVIDIA GeForce RTX 5090 Specs
Graphical
Blender 4.4.0
The Blender benchmark takes 3 scenes and then uses either the CPU or GPU to render them. This is calculated by samples per minute; the higher the number the better performance of the hardware.
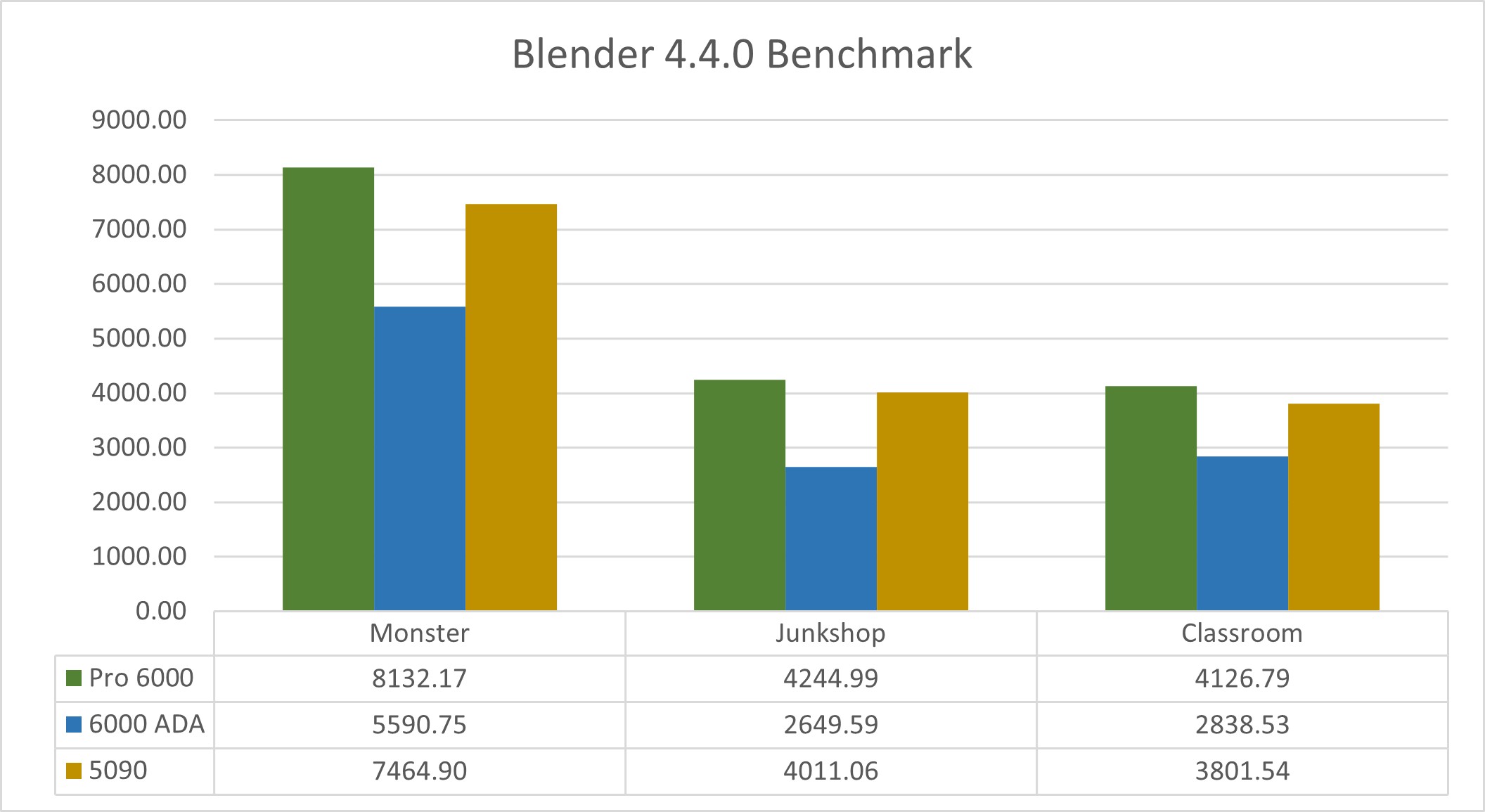
The NVIDIA RTX Pro 6000 consistently outperformed both the RTX 6000 ADA and the GeForce RTX 5090 across all test scenes. In the Monster scene, it delivered over 45% better performance than the RTX 6000 ADA and nearly 9% better than the RTX 5090. In the Junkshop scene, the Pro 6000 extended its lead with more than a 60% improvement over the RTX 6000 ADA and just under 6% over the RTX 5090. The Classroom scene showed similar results, with the Pro 6000 outperforming the RTX 6000 ADA by about 45% and the RTX 5090 by approximately 8.5%.
While it draws the most power at 600W—compared to 575W for the RTX 5090 and 300W for the RTX 6000 ADA—the RTX Pro 6000 delivers top-tier performance, particularly in demanding professional workloads.
vRay 6.00.02
The vRay benchmark uses a pre-determined scene and then either uses the CPU or GPU to render. This is done by samples per minute; the higher the score, the better the performance. GPU has the options to run either CUDA or RTX; CUDA uses parallel compute whereas RTX uses real time rendering.
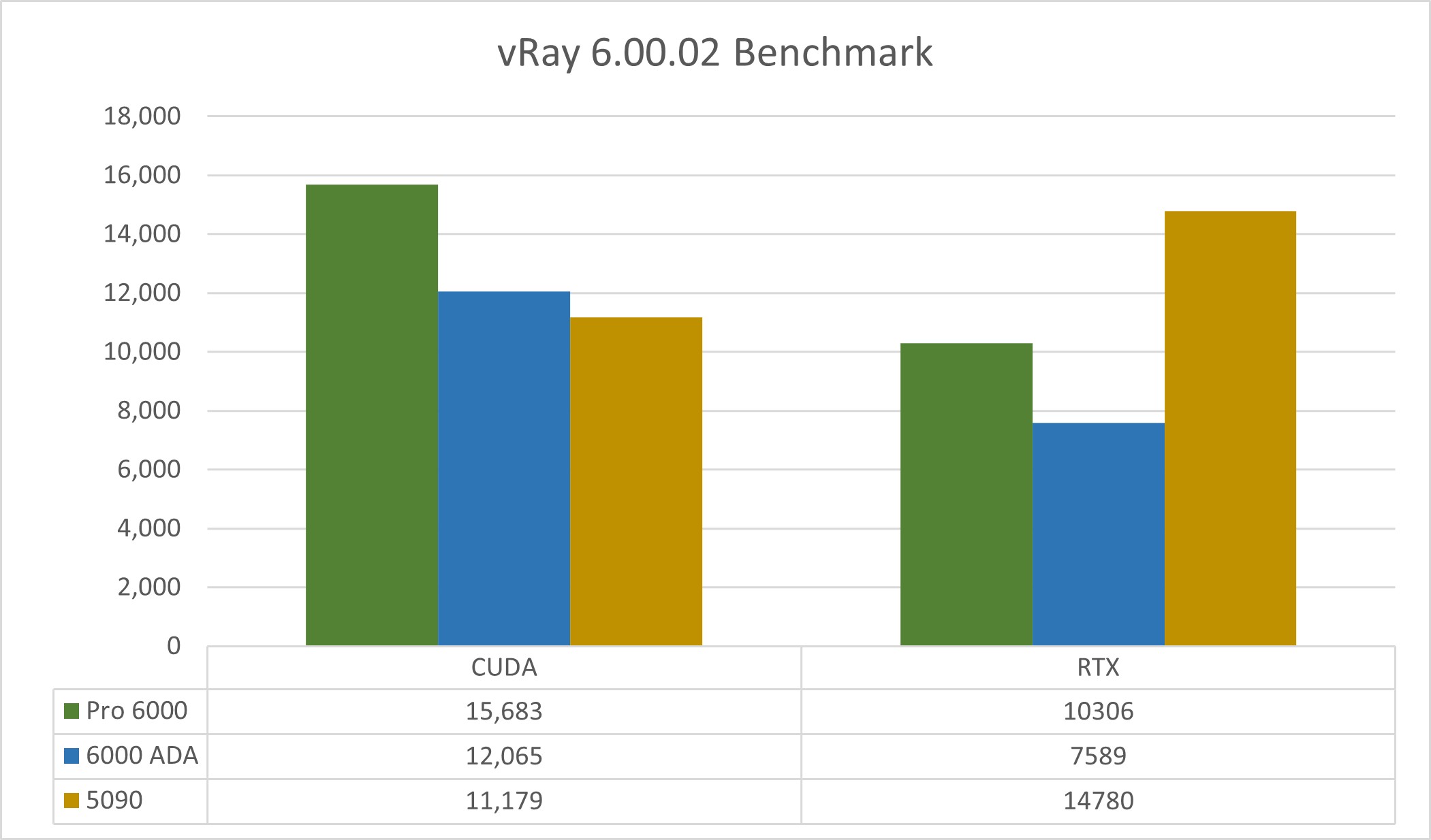
In CUDA performance, the NVIDIA RTX Pro 6000 outpaced the RTX 6000 ADA by nearly 30% and the RTX 5090 by over 40%. However, in RTX performance, while it still beat the RTX 6000 ADA by almost 39%, it was surpassed by the RTX 5090, which delivered just over 30% better performance.
Compute
For the compute testing, we will be comparing the NVIDIA RTX Pro 6000 against the NVIDIA H200 NVL; a GPU specialised for compute workloads and is the first of its kind that uses an enhanced version of High Bandwidth Memory 3 (HBM3e) While both offer high bandwidth, HBM3e excels in raw data throughput and parallel processing, while GDDR7 focuses on delivering high speeds and efficiency for graphics-intensive tasks. We are testing against this card as it has the same TDP and the NVIDIA RTX Pro 6000 as well as to see how it performs compute tasks against the PCIe equivalent of the specialised card for overall performance. The below table has the specs for the competing graphics card:
| Specification | H200 NVL |
| FP64 | 30 TFLOPS |
| FP64 Tensor Core | 60 TFLOPS |
| FP32 | 60 TFLOPS |
| TF32 Tensor Core | 835 TFLOPS |
| BFLOAT16 Tensor Core | 1,671 TFLOPS |
| FP16 Tensor Core | 1,671 TFLOPS |
| FP8 Tensor Core | 3,341 TFLOPS |
| INT8 Tensor Core | 3,341 TFLOPS |
| GPU Memory | 141GB |
| Memory Bandwidth | 4.8TB/s |
| Decoders | 7 NVDEC, 7 JPEG |
| Confidential Computing | Supported |
| Max TDP | Up to 600W (Configurable) |
| Multi-Instance GPUs (MIG) | Up to 7 MIGs @ 16.5 GB each |
| Form Factor | PCIe, Dual-slot air-cooled |
| Interconnect | NVLink (900 GB/s), PCIe Gen5 (128 GB/s) |
| Server Options | NVIDIA MGX™ H200 NVL partner systems |
| NVIDIA AI Enterprise | Add-on Included |
View Datasheet
Realistic GEMM shapes
Realistic General Matrix Multiply (GEMM) shapes are matrix dimensions that reflect real-world usage in areas like deep learning, graphics and scientific computing. Unlike square matrices often used in benchmarks, these shapes are typically non-square and are influenced by practical factors such as batch size, feature dimensions and sequence lengths. This gives a much more accurate output for real world solutions.
The below results were completed with 30 x warmup and 200 x repeats.
| GPU | Precision | Theoretical Peak (Dense) | Actual GEMM Peak (Dense) | Efficiency (Dense) |
| NVIDIA RTX Pro 6000 | ||||
| BF16 | 504 TFLOPS | 404.6 TFLOPS | 80.2% | |
| FP8 | 1,007 TFLOPS | 753.7 TFLOPS | 74.8% | |
| NVIDIA H200 NVL | ||||
| BF16 | 835 TFLOPS | 659.3 TFLOPS | 78.9% | |
| FP8 | 1,670 TFLOPS | 1,198.8 TFLOPS | 71.8% |
The NVIDIA H200 NVL GPU delivers around 66% higher theoretical and actual GEMM performance than the NVIDIA RTX Pro 6000 in both BF16 and FP8. Its actual GEMM throughput is 63% higher in BF16 and 59% in FP8. However, the RTX Pro 6000 is slightly more efficient, achieving 80.2% in BF16 and 74.8% in FP8, compared to the NVIDIA H200 NVL’s 78.9% and 71.8%, respectively.
I/O Memory Bandwidth
The Input/Output (I/O) Memory Bandwidth of the cards was part of our testing.
| GPU | Copy Bandwidth (GB/s) | Time (ms) |
| NVIDIA RTX Pro 6000 | 1466.75 | 23.43 |
| NVIDIA H200 NVL | 4109.32 | 8.36 |
The NVIDIA H200 NVL achieves an I/O memory copy bandwidth of 4109.32 GB/s, which is approximately 181% higher than the NVIDIA RTX Pro 6000's 1466.75 GB/s. Additionally, the NVIDIA H200 NVL completes the transfer in 8.36 ms, significantly faster than the NVIDIA RTX Pro 6000's 23.43 ms, highlighting the H200's superior memory transfer speed and efficiency, being a little over 180% faster.
Image Classification
| Use Case | Metric | NVIDIA RTX PRO 6000 | NVIDIA H200 NVL |
| Image Classification | GPU Utilisation | 96% | 83% |
| Memory Utilisation | 26,446 MiB | 27,113MiB | |
| Power Consumption | 508W | 403.78W | |
| Temperature (°C) | 75.4 | 64.31 | |
| Throughput (img/s) | 1,123 | 1,525 |
In Image Classification, the RTX Pro 6000 has 13% higher GPU utilisation than the NVIDIA H200 NVL. The NVIDIA H200 NVL uses ~2.5% more memory (27,113 MiB vs. 26,446 MiB) but is roughly 26.5% more power-efficient, consuming 403.78 W compared to 508 W. Most importantly, the NVIDIA H200 NVL delivers ~35.8% higher throughput, processing 1,525 images/sec compared to the Pro 6000’s 1,123 images/sec.
Object Detection
| Use Case | Metric | NVIDIA RTX PRO 6000 | NVIDIA H200 NVL |
| Object Detection | GPU Utilisation | 72% | 77% |
| Memory Utilisation | 49,056 MiB | 45,141 MiB | |
| Power Consumption | 370.75W | 256.32W | |
| Temperature (°C) | 64.7 | 57.7 | |
| Throughput (img/s) | 109.26 | 115.69 |
In the Object Detection use case, the NVIDIA H200 NVL has 5% higher GPU utilisation than the RTX Pro 6000 (77% vs. 72%) and is just under 31% more power-efficient (256.32 W vs. 370.75 W). It also delivers ~5.6% higher throughput (115.69 vs. 109.26 images/sec). However, the Pro 6000 uses a little under 8.7% more memory (49,056 MiB vs. 45,141 MiB). Overall, the NVIDIA H200 NVL outperforms the Pro 6000 in efficiency and speed.
BERT Squad
| Use Case | Metric | NVIDIA RTX PRO 6000 | NVIDIA RTX H200 NVL |
| BERT Squad | GPU Utilisation | 98% | 98% |
| Memory Utilisation | 75,148 MiB | 75,215 MiB | |
| Power Consumption | 557.51W | 502.05W | |
| Temperature (°C) | 78.48 | 67.73 | |
| Throughput (img/s) | 194.26 | 364.99 |
In the BERT Squad workload, both GPUs show identical GPU utilisation (98%) and nearly the same memory usage (75,148 MiB vs. 75,215 MiB). However, the NVIDIA H200 NVL is around 10% more power-efficient (502.05 W vs. 557.51 W) and most notably, it delivers 87.8% higher throughput, processing 364.99 sentences/sec compared to the Pro 6000’s 194.26, making the NVIDIA H200 NVL significantly faster and more efficient overall.
Image Segmentation
| Use Case | Metric | NVIDIA RTX PRO 6000 | NVIDIA H200 NVL |
| Image Segmentation (BRATS) | GPU Utilisation | 54% | 46% |
| Memory Utilisation | 24,026 MiB | 23,719 MiB | |
| Power Consumption | 309.23W | 217.01W | |
| Temperature (°C) | 48.04 | 52.13 | |
| Throughput (img/s) | 17.48 | 17.04 |
In the BRATS image segmentation task, the NVIDIA RTX Pro 6000 shows ~17.4% higher GPU utilisation (54% vs. 46%) and just under 1.3% higher memory usage (24,026 MiB vs. 23,719 MiB). It also delivers a little over 2.5% higher throughput (17.48 vs. 17.04 volumes/sec).However, the NVIDIA H200 NVL is just over 29.8% more power-efficient, consuming 217.01 W compared to 309.23 W. Overall, the NVIDIA RTX Pro 6000 performs slightly better in usage and speed, while the NVIDIA H200 NVL is more power-efficient.
Deepseek - Decoder - GovtScrolls Dataset
| Use Case | Metric | NVIDIA RTX PRO 6000 | NVIDIA H200 NVL |
| DeepSeek Decoder (GovtScrolls) | GPU Utilisation | 92% | 89% |
| Memory Utilisation | 64,612 MiB | 64,705 MiB | |
| Power Consumption | 441.88W | 371.50W | |
| Temperature (°C) | 67.35 | 63.33 | |
| Throughput (img/s) | 4.08 | 11.34 |
In the DeepSeek Decoder task, the NVIDIA RTX Pro 6000 has ~3.4% higher GPU utilisation (92% vs. 89%), while the NVIDIA H200 NVL uses slightly more memory (64,705 MiB vs. 64,612 MiB). The NVIDIA H200 NVL is just over 15.9% more power-efficient (371.50 W vs. 441.88 W) but most significantly, it achieves just under 178% higher throughput, processing 11.34 sentences/sec compared to the NVIDIA RTX Pro 6000’s 4.08, making the NVIDIA H200 NVL vastly superior in performance and efficiency for this workload.
Note: The NVIDIA H200 NVL has a higher TFLOPS than the NVIDIA RTX Pro 6000 despite the Pro having more GPU Utilisation.
Overall, for AI workloads, the NVIDIA RTX PRO™ 6000 does come up short against the specialised NVIDIA H200 NVL however, it is capable of holding its own. This is especially important to consider that it has the capability to perform graphical workloads and outperform most other cards, whereas the NVIDIA H200 NVL has no such functionality.
Conclusion
The NVIDIA RTX PRO™ 6000 Blackwell Workstation Edition is a powerhouse GPU built for professional workloads, not casual use. With 96 GB of ECC GDDR7 memory, massive core counts and top-tier ray tracing and AI capabilities, it mostly outperforms other GPUs of its kind by a significant margin and can keep up with AI capabilities of even the most demanding workloads.
Boston Labs is dedicated to helping our customers make informed decisions when choosing the right hardware, software and complete solutions tailored to their unique requirements and test drives of the NVIDIA RTX PRO™ 6000 are already available via our onsite R&D and test facility. The team are ready to enable customers to test-drive the latest technology on-premises or remotely via our fast internet connectivity.
If you are ready to start your workstation journey, then please get in touch either by email or by calling us on 01727 876100 and one of our experienced sales engineers will happily guide you to your perfect tailored solution and invite you for a demo.
Author
Peter Wilsher
Field Application Engineer
Boston Limited